
Abstract
We propose a cross-modal distillation framework, PartDistill, which transfers 2D knowledge from vision-language models (VLMs) to facilitate 3D shape part segmentation. PartDistill addresses three major issues in this task, namely \(\boldsymbol{\mathcal{I}_1}\): the lack of 3D segmentation in invisible or undetected regions in the 2D projections, \(\boldsymbol{\mathcal{I}_2}\): inconsistent 2D predictions by VLMs, and \(\boldsymbol{\mathcal{I}_3}\): the lack of knowledge accumulation across different 3D shapes. PartDistill consists of a teacher network that uses a VLM to make 2D predictions and a student network that learns from the 2D predictions while extracting geometrical features from multiple 3D shapes to carry out 3D part segmentation. A bidirectional distillation, including forward and backward distillations, is carried out within the framework, where the former forward distills the 2D predictions to the student network, and the latter improves the quality of the 2D predictions, which subsequently enhances the final 3D segmentation. Moreover, PartDistill can exploit generative models that facilitate effortless 3D shape creation for generating knowledge sources to be distilled. Through extensive experiments, PartDistill boosts the existing methods with substantial margins on widely used ShapeNetPart and PartNetE datasets, by more than 15% and 12% higher mIoU scores, respectively.
Method
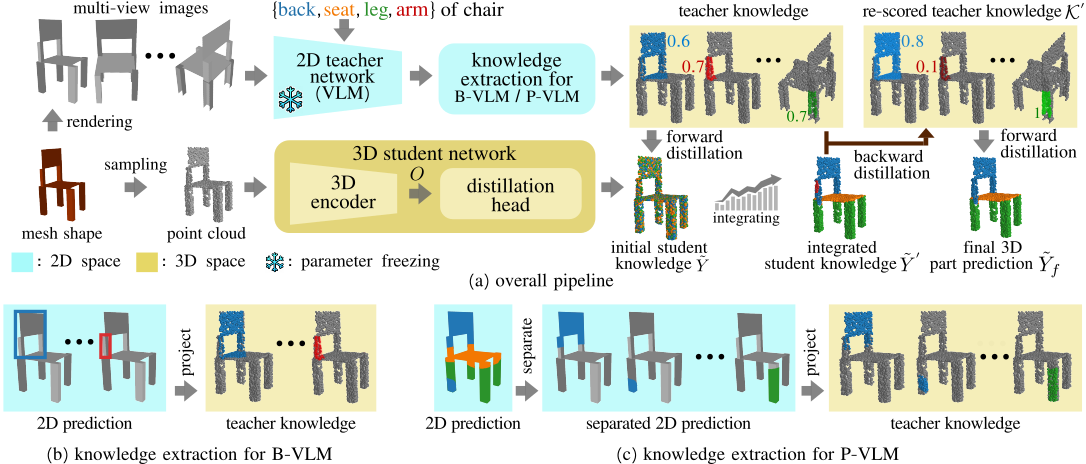
Overview of the proposed method. (a) The overall pipeline where the knowledge extracted from a vision-language model (VLM) is distilled to carry out 3D shape part segmentation by teaching a 3D student network. Within the pipeline, backward distillation is introduced to re-score the teacher’s knowledge based on its quality and subsequently improve the final 3D part prediction. (b) & (c) Knowledge is extracted by back-projection when we adopt (b) a bounding-box VLM (B-VLM) or (c) a pixel-wise VLM (P-VLM).
Experimental Results
Qualitative results
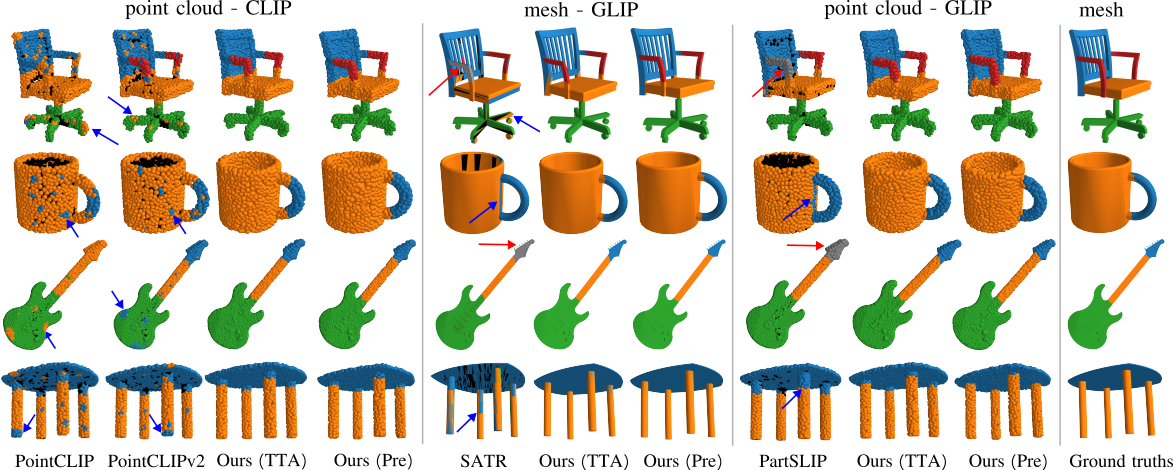
Visualization of the zero-shot segmentation results, drawn in different colors, on the ShapeNetPart dataset. We render PartSLIP results on the ShapeNetPart data to have the same visualization of shape inputs. While issue \(\boldsymbol{\mathcal{I}_1}\): occluded and undetected regions are shown with black and gray colors, respectively, the blue and red arrows highlight several cases of issues \(\boldsymbol{\mathcal{I}_2}\): negative transfer and \(\boldsymbol{\mathcal{I}_3}\): lack of knowledge accumulation.
Quantitative results
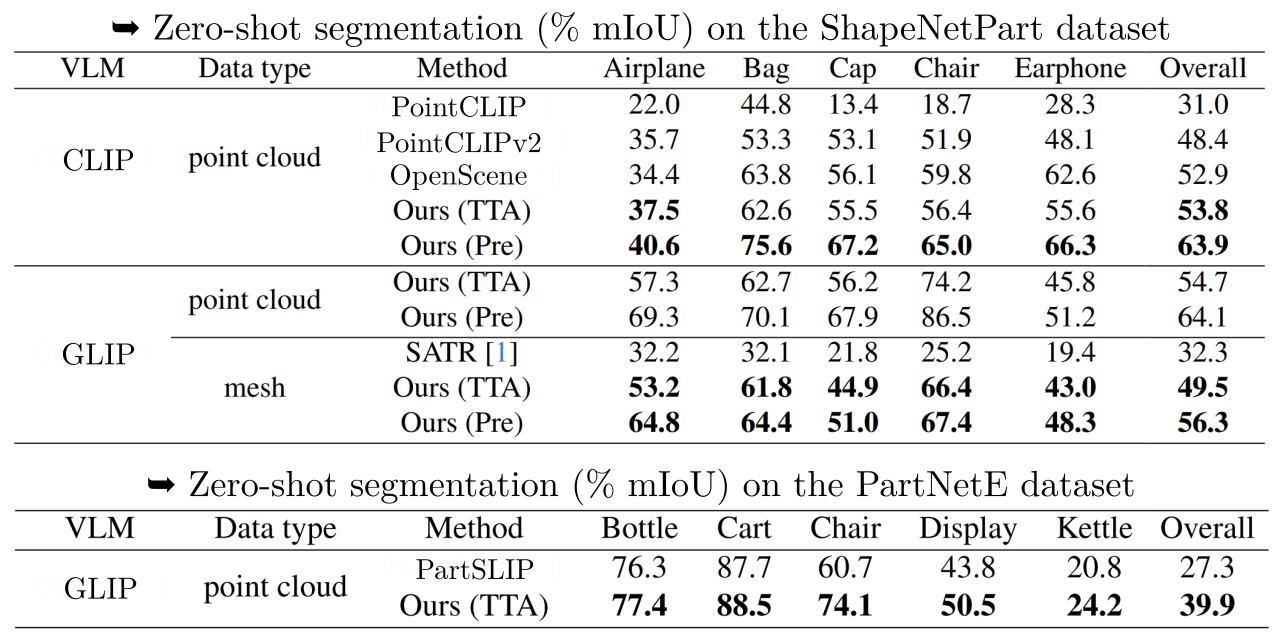
We carry out the comparison separately to ensure fairness, based on the employed VLM model and the shape data type, i.e., point cloud or mesh data, as shown in above tables. In the upper table, we provide two versions of our method, including test-time alignment (TTA) and prealignment (Pre) with a collection of shapes from the trainset data, while in the lower table, only TTA version is provided since the PartNetE dataset does not provide train-set data. From the tables, our method demonstrates its consistency on surpassing the benchmark methods.

Regarding leveraging generative models, if a collection of shapes does not exist, generative models can be employed for shape creation and subsequently used in our method as the knowledge source. From the table above, such approach (second row) achieves competitive results compared to distilling from the train-set data (first row). Furthermore, when a collection of shapes is available, generated data can be employed as supplementary knowledge sources, which can improve the performance (third row).
Acknowledgment
This work was supported in part by the National Science and Technology Council (NSTC) under grants 112-2221-E-A49-090-MY3, 111-2628-E-A49-025-MY3, 112-2634-F-006-002 and 112-2634-F-A49-007. This work was funded in part by MediaTek and NVIDIA.
BibTeX
@inproceedings{umam2023partdistill,
title = {PartDistill: 3D Shape Part Segmentation by Vision-Language Model Distillation},
author = {Umam, Ardian and Yang, Cheng-Kun and Chen, Min-Hung and Chuang, Jen-Hui and Lin, Yen-Yu},
booktitle = {IEEE/CVF International Conference on Computer Vision (CVPR)},
year = {2024},
}